
WIRED's Article Paywall Is Broken
Client side JavaScript is not a good security practice


Disclaimer: I have repeatedly contacted Wired to inform them of this issue and have never received a response. I also indirectly pay for Wired content via an Apple News+ subscription.
I've noticed that the paywall on Wired.com does not work as I'd expect. The content of an article loads before the paywall can check to see if the reader should have access to the article. See below where the text of the article becomes visible before disappearing.
You can try this yourself by loading a few articles on Wired.com till you exhaust the “free articles” limit. The very next time you load an article you should see this “please subscribe” notice:
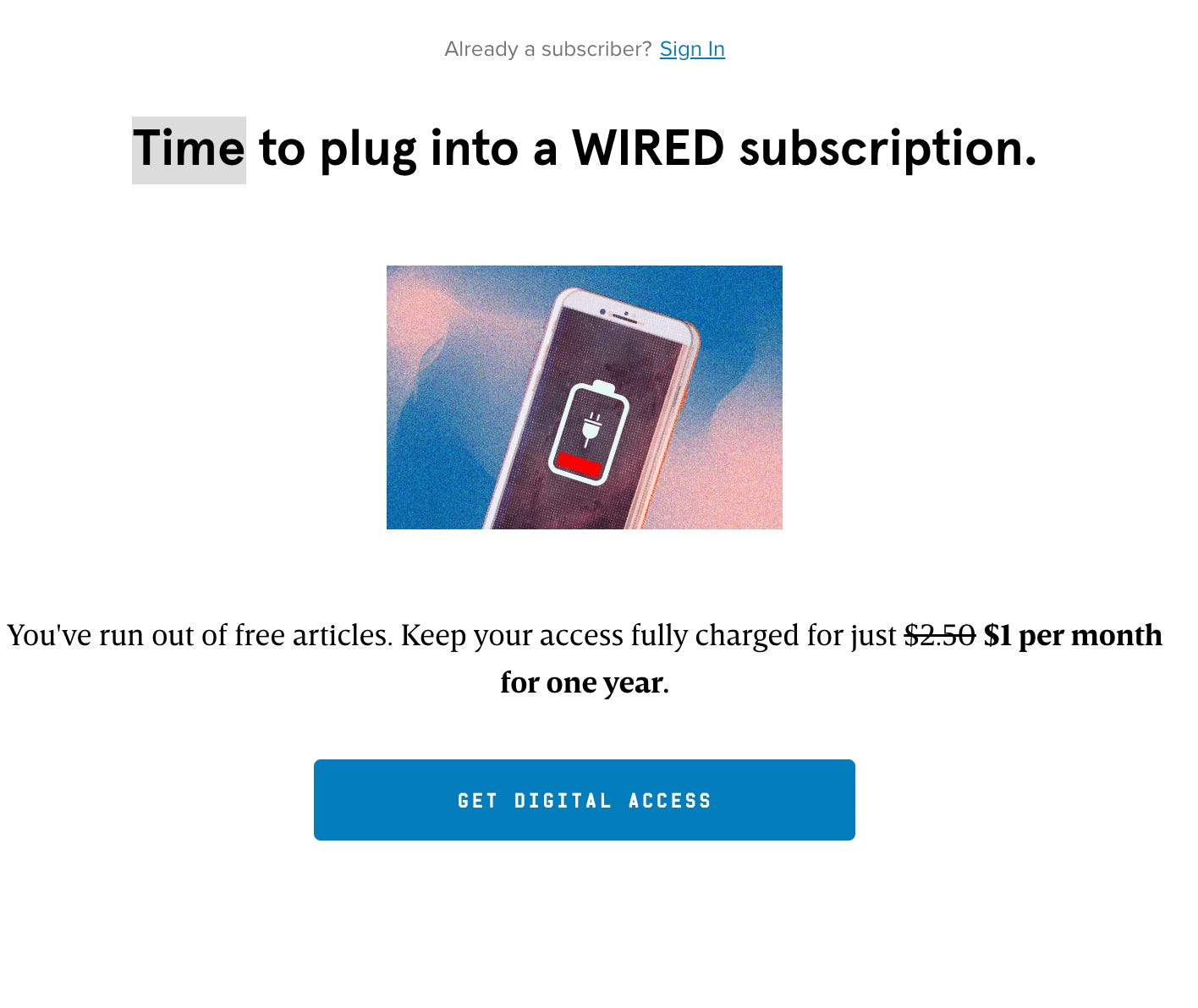
but only after you see the full text of the article flicker on the page.
The Threat… for Wired
Simply pausing execution of the JavaScript on the page will allow a non-subscriber to read as many full articles as they wish without ever paying anything. See below how clicking a single button in the developer tools of your browser will prevent the paywall from executing the code necessary to hide the article text.
Another way to verify this is by running a CuRL command like the one below and you'll see the full text of the article is returned immediately in the HTTP response.
curl https://www.wired.com/story/signal-tips-private-messaging-encryption/Why is a JavaScript paywall a bad idea?
Using JavaScript to obfuscate the article text is not secure against exploitation. JavaScript is code that executes in the reader’s browser. The reader can manipulate anything they want in the browsers - it’s on their machine! A secure alternative would be to implement the paywall logic on the server side.
A server side paywall would first check to see if the user is logged in. If they are then the full text of the article would be returned. If not, then only the first two or three paragraphs of the article would be returned. This would prevent any malicious manipulation in the reader’s browser from accessing the full article text without being a paying subscriber.
Wired is most likely using server side generation (SSG) to create a full webpage for each unique article thereby allowing better caching in content distribution networks for faster page load times. Or it could be that the paywall was added later and for ease and convenience it was implemented client side (in JavaScript) to avoid having to modify the server side code.
Either way, while Wired can benefit from search engine optimization and indexing, they have sacrificed the security of their content and the reliability of their revenue stream.
The Threat… for Journalism
I believe independent journalism is a necessity in today’s world. I won’t argue why, as AG Sulzberger does an excellent job of that here - https://www.nytco.com/press/journalisms-essential-value/. But I will point out one of the things he says in his essay.
The most important safeguard of an independent press is a strong and sustainable press. We need to build up the business model for reported journalism
A sustainable press is one that has a working business model - part of that business model for Wired is subscription revenue. If readers can easily bypass the paywall, then there is little incentive to pay.
We are all aware of the value that a free and independent press holds. It is one of the cornerstones of American democracy. Beyond ideals, the press is woven into the fabric of our culture. There is a reason why late night hosts like Seth Meyers or Stephen Colbert will use news articles to punctuate their jokes.
Often even the news found on social media is just an aggregation of original news published in text by a handful of the reputable organizations you’d probably recognize by name at a glance. AG Sulzberger motivates why original journalism is so important, now more than ever.
common facts, a shared reality, and a willingness to understand our fellow citizens across tribal lines are the most important ingredients in enabling a diverse, pluralistic society to come together to self-govern. For that, as much as anything, we need principled, independent journalists
And he continues by explaining why original journalism is at risk.
Inside the industry, newspapers continue to shutter and the number of working journalists has dropped by tens of thousands over the past fifteen years. The newspapers that endure, embracing the approach of many of the digital news organizations that have emerged, have often felt compelled to shift increasingly scarce resources away from expensive original reporting to far cheaper but less journalistically nutritious efforts like punditry, aggregation, and clickbait.
Punditry, aggregation, and clickbait - that defines information on the internet fairly well in today’s world. The trend pushing news away from independent journalism is already there. It is my belief that LLMs will fuel this trend and that properly utilized, functioning paywalls (and stronger Terms of Service) can be a bulwark against further decline into the machine driven us-vs-them societal cesspit.
Here are a few ways that left unchecked, LLM hype could hasten the demise of independent journalism.
An LLM regurgitates an oft repeated falsehood in contrast with the truth as reported by independent journalism.
LLM summaries diverting readership from original news sources.
Increased deadline pressure to compete with LLM news desks undermines editorial standards for independent journalism.
Hyper partisan and hyper local LLMs generate engagement centric feedback loops further siloing people into tribal units.
Without a working paywall, it becomes much easier for automated systems to download large quantities of high quality human written text for purposes like LLM training. In fact, this is at the core of the lawsuit between The New York Times and OpenAI.
So should we ban LLMs from journalism?
No. It is not practical nor wise to prevent adoption of a useful tool. Instead, care should be taken to extract benefits that exceed the cost when the tool is inevitably used. For a publisher like Wired, this means extracting benefits - licensing fees - from the companies that want to use their text to train their models.
Wired’s parent company Conde Nast partnered with OpenAI - https://openai.com/index/conde-nast/ in August 2024. Even Wired wrote about it - https://www.wired.com/story/conde-nast-openai-deal/. As far as I can tell, there is a licensing deal that allows OpenAI to surface Conde Nast property (Wired is a property of Conde Nast) articles in ChatGPT. Most likely this is a retrieval augmented generation (RAG) system where the LLM takes as input additional realtime sources (like a Wired article) to improve the quality of its output. Because RAG works without having to retrain the entire LLM from scratch, there is an opportunity for Wired via Conde Nast to monetize their content as training data when those LLMs do need to be retrained.
Maybe this is already happening and I’m just talking to myself, but without knowing more about the deal, it is impossible to tell if Wired via Conde Nast has left the door open for companies like OpenAI to take the “freely and publicly available” articles for use as training data.
Who would know if they did? What we do know is that is exactly what happened to The New York Times.
Using news to train LLMs
The New York Times has a functioning paywall. The exploit detailed above does not work with the articles they publish, and still their articles were scraped in large quantities to train LLMs. From what I can glean, OpenAI did not notify The New York Times of their intent to train LLMs using the copyrighted text of published articles. Here is an excerpt from The New York Times first 2023-12-27 - Complaint - Document #1.
Defendants’ unlawful use of The Times’s work to create artificial intelligence products that compete with it threatens The Times’s ability to provide that service. Defendants’ generative artificial intelligence (“GenAI”) tools rely on large-language models (“LLMs”) that were built by copying and using millions of The Times’s copyrighted news articles, in-depth investigations, opinion pieces, reviews, how-to guides, and more.
The New York Times currently has explicit language in the Terms of Service that forbid using their content in the training of AI systems including LLMs. See Section 4. Prohibited Use of the Services, Subsection 4.1(3) below:
Without NYT’s prior written consent, you shall not:
(3) use the Content for the development of any software program, model, algorithm, or generative AI tool, including, but not limited to, training or using the Content in connection with the development or operation of a machine learning or artificial intelligence (AI) system (including any use of the Content for training, fine tuning, or grounding the machine learning or AI system or as part of retrieval-augmented generation).
A working paywall is not a guarantee that content will be safe from unintended uses, but it does make it much harder to use that content in a manner inconsistent with the publisher’s intent.
Paywall not needed - The "fair use” argument
One could argue as OpenAI does, that news articles fall under the Fair Use legal doctrine. If that argument holds, then there is nothing to prevent a company from using the millions of lines of high quality human written copyrighted text to train commercial systems that generate text.
One interesting thing to note is that OpenAI does not dispute that they trained their systems on articles of The New York Times, but only that they have Fair Use of the text when they trained their LLMs. Let’s take a quick look at what Fair Use is and how it is defined. https://www.copyright.gov/fair-use/
Fair Use is a legal doctrine that promotes freedom of expression by permitting the unlicensed use of copyright-protected works in certain circumstances
There are four factors that are considered when evaluating a question of fair use:
Purpose and character of the use, including whether the use is of a commercial nature or is for nonprofit educational purposes.
Nonprofit educational and noncommercial uses of copyrighted material are more likely to support Fair Use compared to a for-profit non-educational use of copyrighted material.Nature of the copyrighted work.
A factual work like a news article is more likely to support Fair Use compared to a creative work like a song or novel.Amount and substantiality of the portion used in relation to the copyrighted work as a whole.
Using a small amount of copyrighted material is more likely to support Fair Use compared to use that includes a large portion of the copyrighted work.
Effect of the use upon the potential market for or value of the copyrighted work.
The smaller the harm to the existing or future market of the copyright owner’s original work the more likely Fair Use of the unlicensed copyrighted material can be claimed.
When we look at a company like OpenAI and the products that they allegedly trained on copyrighted material, the scorecard looks like this.
Purpose and character of the use, including whether the use is of a commercial nature or is for nonprofit educational purposes. (Less likely to be Fair Use)
The use is for-profit. OpenAI used to be a non-profit but it has been evolving its corporate structure to take on additional funding and that has led to a transformation of part of itself into a for-profit - https://openai.com/index/why-our-structure-must-evolve-to-advance-our-mission/.
I would also claim that generative LLMs at their core are also non-educational. They can be used in an educational context but fundamentally they are a tool to generate text. We already know that LLMs can hallucinate and generate realistic facts and answers to questions without the user being aware that the LLM created something fictitious. And there are open questions about how these tools impact the educational experience of students. We may be in the midst of a global dumbing-down. Time will tell.
Nature of the copyrighted work. (More likely to be Fair Use)
The copyrighted work in question here are news articles so this is a clear case for arguing Fair Use.
Amount and substantiality of the portion used in relation to the copyrighted work as a whole. (Less likely to be Fair Use)
OpenAI used a huge corpus of news data. The New York Times alleges it was millions of articles. If they had only taken a handful that would have been one thing, but they took a lot more than a handful.
Effect of the use upon the potential market for or value of the copyrighted work. (Less likely to be Fair Use in the future)
Current impact to the news market is not directly measurable. It is likely small but also growing. Traditional news has been under threat even before generative AI technology came along. There is a growing preference for punditry and aggregation. https://www.nytco.com/press/journalisms-essential-value/. AI summaries of news will fuel this trend which makes the argument of future impact to original reporting more tangible.
Paywall definitely needed
Even if Fair Use claims are deemed legal from the standpoint of training LLMs, there is still the impact to baseline subscription revenue from an easy to bypass paywall.
There are many reasons why an individual or organization might decide to bypass a paywall. Maybe someone decides to set up a clone of Wired where they can collect cheaper - but non-zero - subscription fees. Maybe a hacktivist decides to post the full corpus of Wired online in a huge data dump just because.
Whatever the reason, there will be real consequences for Wired, its staff, and the ideal of editorial independence - ideals don’t pay the electricity bills.
The Nitty Gritty - Dragnet and Newspaper
One of the most recent documents from the litigation between The New York Times and OpenAI detail how OpenAI got the text for the articles. 2025-04-04 - Memorandum & Opinion - Document #514 - Page 25
CIR states that OpenAI, in developing Webtext, “used sets of algorithms called Dragnet and Newspaper to extract text from websites,” and specifically alleges that “Dragnet’s algorithms are designed to separate the main article content’ from other parts of the website, including ‘footers’ and ‘copyright notices,’ and allow the extractor to make further copies only of the ‘main article content.’”
There were no links, but I think these are the githubs.
https://github.com/dragnet-org/dragnet_data
https://github.com/codelucas/newspaper
https://github.com/AndyTheFactory/newspaper4k